Intro
Overview
What is GraphQL
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
Schema
The schema defines the types of data that can be queried or mutated in a GraphQL API, as well as the relationships between them. It serves as a contract between the client and the server, specifying what operations are supported and what data can be retrieved or modified.
type User {
id: ID!
username: String!
email: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
content: String!
author: User!
}
// Query
type Query {
user(id: ID!): User
post(id: ID!): Post
}
// Mutation
type Mutation {
createUser(input: CreateUserInput!): User!
updateUser(id: ID!, input: UpdateUserInput!): User!
deleteUser(id: ID!): Boolean!
}Mutation & Query
Queries in GraphQL are used to fetch data from the server. They resemble JSON objects and specify the fields and nested objects you want to retrieve. Every GraphQL API must have a set of queries defined to enable clients to request data.
query {
user(id: "123") {
name
email
posts {
title
content
}
}
}
In this example, the query requests the name and email of a user with ID 123, as well as the titles and content of their posts.
2. Mutations:
Mutations are operations used to modify data on the server, such as creating, updating, or deleting resources. They follow a similar structure to queries but are used for modifying data instead of reading it.
Every GraphQL API should include mutations to enable clients to perform data modifications.
mutation {
createUser(input: { username: "newuser", email: "newuser@example.com", password: "password123" }) {
id
username
email
}
}You make a request and the server is in charge of validating it, and making sure that you abide to a predefined structure.
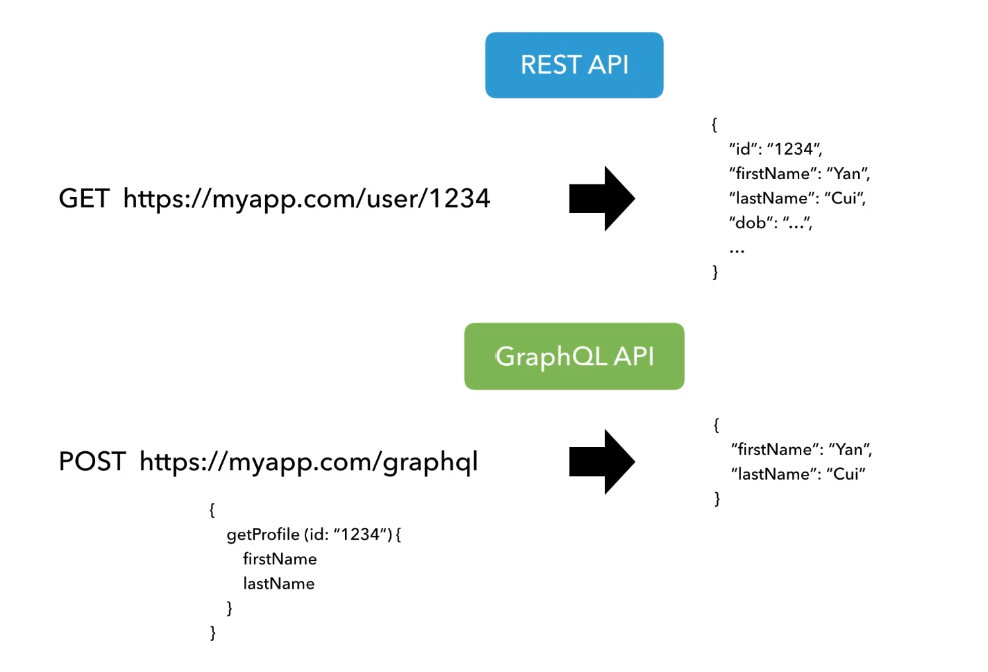
Rest Vs Graphql
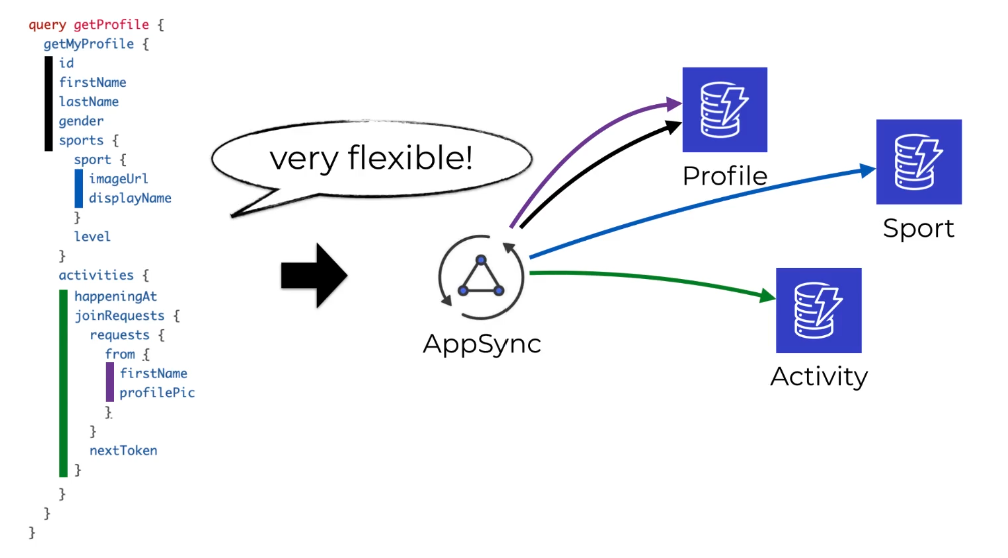
What is the N+1 query problem?
The chief symptom of this problem is that there are many, many queries being performed. Typically, this happens when you structure your code so that you first do a query to get a list of records, then subsequently do another query for each of those records. You might expect that many small queries would be fast and one large, complex query will be slow. This is rarely the case. In practice, the opposite is true. Each query has to be sent to the database, the database has to perform the query, then it sends the results back to your app.
The more queries you perform, the more time it takes to get the results back, with each trip to the database server taking time and resources. In contrast, a single query, even if it’s complex, can be optimized by the database server and only requires one trip to the database, which will usually be much faster than many small queries.
BFFs
BFFs (Backends For Frontends) are a design pattern where each frontend client, such as a web application or mobile app, has its dedicated backend service. This approach allows developers to tailor backend logic and data fetching specifically to the needs of each frontend,

With graphql, there is no need for BFFs, you have the flexibility to get just what you need, since GraphQL is a Strongly typed contract between the client and server
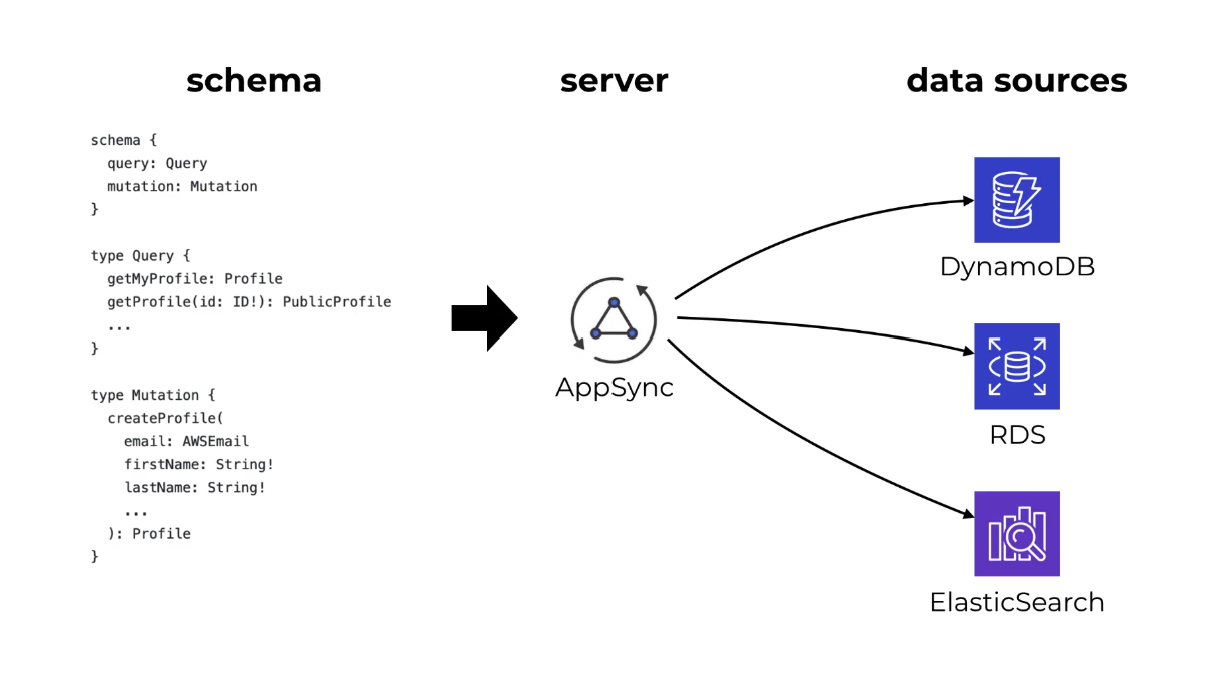
AppSync
Fully managed graphQL service Caching, monitoring/Logging WebSockets
AWS AppSync is a fully managed service provided by Amazon Web Services (AWS) that enables developers to build scalable and secure GraphQL APIs to interact with various data sources. It simplifies the process of creating GraphQL APIs by handling the heavy lifting of infrastructure provisioning, scaling, and maintenance, allowing developers to focus on building applications.
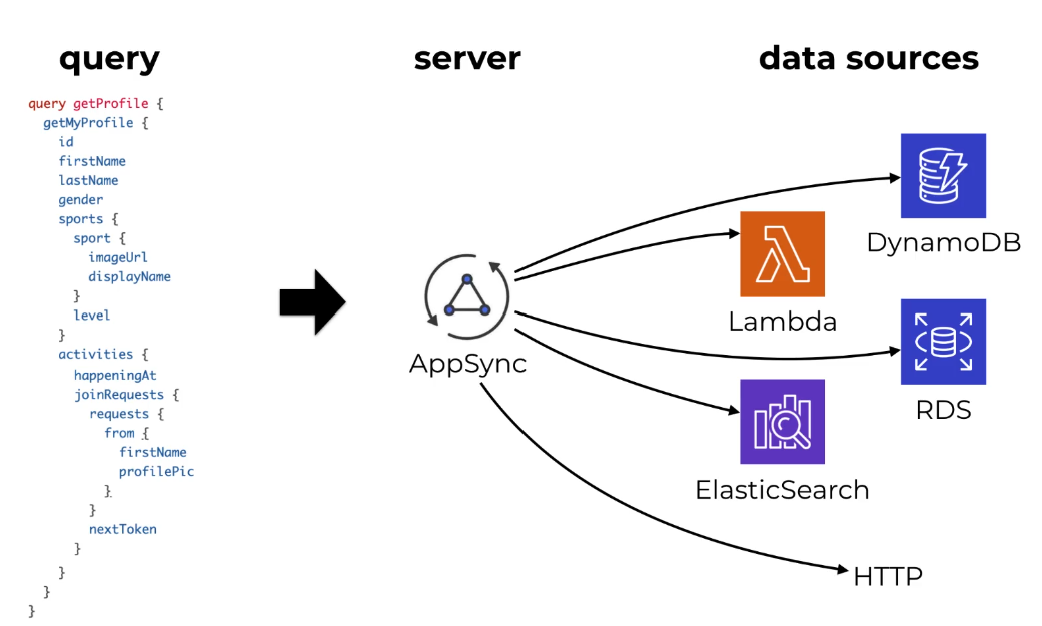
AppSync Supports many Data sources

What can you do with AppSync ?
Out of the box, AWS AppSync Provides 🔥 Fully Managed GraphQL Service 🔥 Caching 🔥 Monitoring/Logging 🔥 WebSockets 🔥 WAF : Web application firewall 🔥 Integration with AWS Services. 🔥 Authentication.

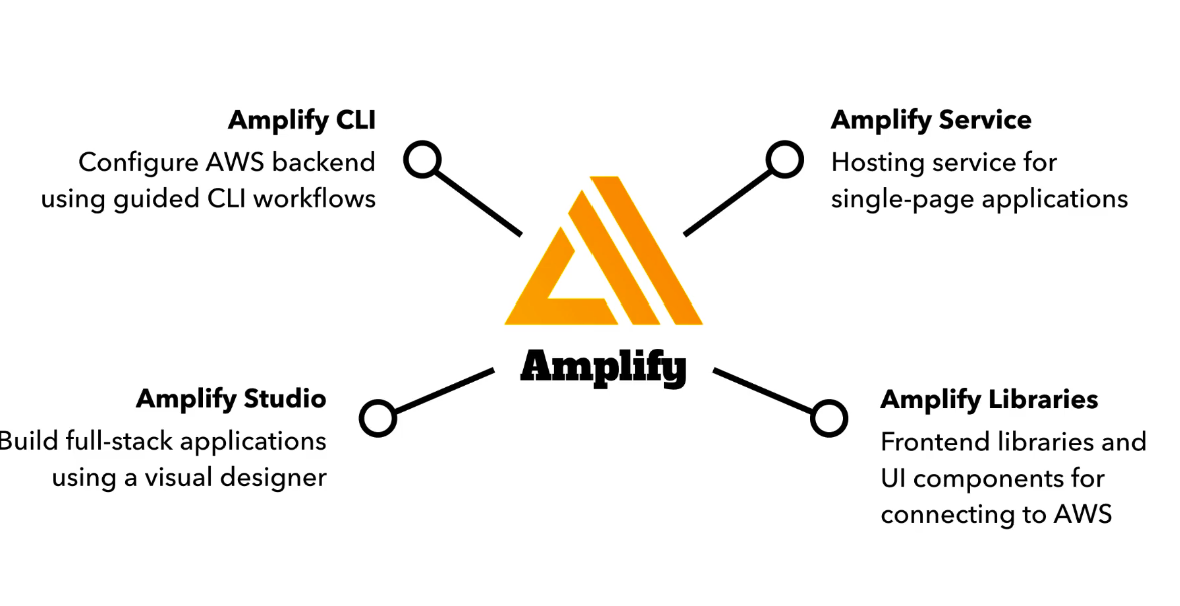
Amplify
AWS Amplify is a set of tools and services provided by Amazon Web Services (AWS) to help developers build scalable and secure cloud-powered applications. It offers a comprehensive suite of features and functionalities that simplify the development process for web and mobile applications, including authentication, data storage, real-time updates, and more.
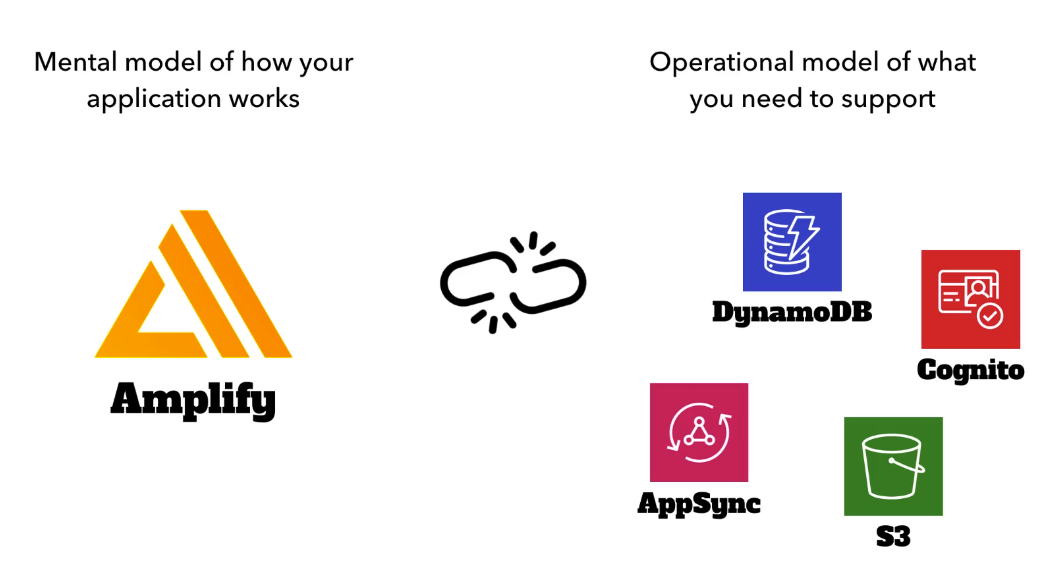
Amplify adds a nice abstraction over different services and how they are added to your app, but it's quite dangerous if you don't understand the underlying working principles. Debugging your app when things fail will be close to impossible if you only rely on Amplify's abstraction.
What you need is to know how the underlying tools works so that you can understand and fix things later when they break.
DynamoDB
Amazon DynamoDB is a fully managed NoSQL database service provided by Amazon Web Services (AWS). It offers fast and predictable performance with seamless scalability, making it ideal for a wide range of applications, from small-scale projects to large-scale enterprise applications.
-
Fully Managed: DynamoDB is a fully managed service, meaning AWS handles administrative tasks such as hardware provisioning, setup, configuration, replication, backups, and maintenance. This allows developers to focus on building applications rather than managing infrastructure.
-
Scalable: DynamoDB is designed for seamless scalability. It automatically scales to handle any level of traffic without the need for manual intervention. Developers can easily increase or decrease the throughput capacity of their tables to accommodate changes in workload demands.
-
High Performance: DynamoDB offers single-digit millisecond latency for read and write operations, making it well-suited for applications that require low-latency access to data. It achieves this high performance by using SSD storage and distributed architecture.
-
Flexible Data Model: DynamoDB is a NoSQL database that supports flexible schema designs. It allows developers to store and retrieve semi-structured data, such as JSON documents, without requiring a predefined schema. This flexibility enables agile development and iteration of applications.
-
Scalable Data Model: DynamoDB supports both key-value and document data models. It allows developers to create tables with primary keys and secondary indexes to query and retrieve data efficiently. DynamoDB also supports composite primary keys and composite indexes for more complex querying requirements.
-
Consistent Performance: DynamoDB offers consistent performance regardless of the volume of data stored or the level of traffic. It uses adaptive capacity management to maintain consistent throughput and latency for read and write operations.
-
Durability and Availability: DynamoDB provides built-in data durability and availability features. It replicates data across multiple Availability Zones within a region to ensure high availability and fault tolerance. DynamoDB also offers backup and restore capabilities for data protection and disaster recovery.
-
Security: DynamoDB offers robust security features to protect data at rest and in transit. It supports encryption at rest using AWS Key Management Service (KMS) and encryption in transit using SSL/TLS. DynamoDB also integrates with AWS Identity and Access Management (IAM) for fine-grained access control.
-
Integration with AWS Ecosystem: DynamoDB seamlessly integrates with other AWS services, such as AWS Lambda, Amazon S3, Amazon Redshift, Amazon EMR, and more. This integration enables developers to build scalable and resilient applications using a combination of AWS services.
Use Cases for Amazon DynamoDB:
-
Web and Mobile Applications: DynamoDB is well-suited for building web and mobile applications that require low-latency access to data and seamless scalability to accommodate growing user bases and workloads.
-
Gaming Applications: DynamoDB is commonly used in gaming applications to store player profiles, game state, leaderboards, and other game-related data. Its scalability and performance make it suitable for handling real-time interactions and massive multiplayer environments.
-
IoT Applications: DynamoDB is used in Internet of Things (IoT) applications to store sensor data, telemetry data, device metadata, and other IoT-related data. Its ability to handle high throughput and large volumes of data makes it ideal for IoT use cases.
-
Ad Tech and Marketing Analytics: DynamoDB is used in ad tech and marketing analytics applications to store and analyze user interactions, clickstream data, campaign metrics, and other advertising-related data. Its scalability and performance enable real-time analytics and personalized targeting.
-
Content Management Systems (CMS): DynamoDB is used in content management systems to store and retrieve content data, user profiles, session information, and other CMS-related data. Its flexible data model and scalability make it suitable for handling dynamic and variable content structures.
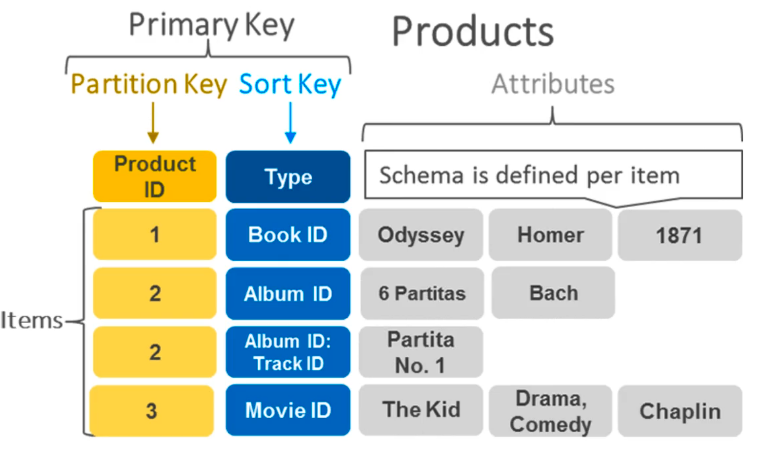
Tables vs Items vs Attributes
Tables:
- Tables: In DynamoDB, data is stored in tables, which are collections of items. Each table in DynamoDB is schema-less, meaning that each item in the table can have a different set of attributes. Tables are created and managed through the DynamoDB console, CLI, or SDK.
Items:
- Items: An item is a single data record in a DynamoDB table. (It’s analogous to a row in a relational database). Each item consists of one or more attributes, which are key-value pairs. Items can vary in structure, meaning that different items in the same table can have different attributes.
- Each item must have a primary key, which uniquely identifies the item within the table.
Attributes:
- Attributes: Attributes are the key-value pairs that make up the data within DynamoDB items. Each attribute has a name and a value. Attributes can be of various data types, including string, number, binary, boolean, list, map, or null. DynamoDB is schema-less, so attributes can vary from item to item within the same table.
Modes of provisioning
In Amazon DynamoDB, there are two main modes for managing throughput capacity: On-Demand and Provisioned. These modes determine how you provision and pay for the read and write capacity of your DynamoDB tables.
On-Demand Mode
-
On-Demand: With On-Demand mode, DynamoDB automatically scales your table’s read and write capacity based on the actual traffic patterns of your application. You do not need to specify read and write capacity units (RCUs and WCUs) in advance. Instead, DynamoDB charges you for the actual read and write activity your application performs, measured in read and write request units (RRUs and WRUs).
-
Key Features:
-
No capacity planning required: DynamoDB automatically scales capacity up or down in response to traffic patterns.
-
Pay-per-request pricing: You are billed for the read and write requests your application makes, rather than pre-provisioned capacity.
-
Suitable for unpredictable workloads: On-Demand mode is ideal for applications with unpredictable traffic patterns or short-term spikes in activity.
-
Provisioned Mode:
-
Provisioned: In Provisioned mode, you specify the read and write capacity units (RCUs and WCUs) that you expect your application to require. DynamoDB provisions and allocates resources accordingly, ensuring that your table can handle the expected throughput. You are charged based on the provisioned capacity, regardless of whether your application uses all of the provisioned capacity.
-
Key Features:
- Predictable pricing: You pay a fixed rate based on the provisioned capacity, regardless of the actual traffic to your table.
- Control over capacity: You can manually adjust the provisioned capacity based on your application’s needs, either up or down.
- Suitable for predictable workloads: Provisioned mode is ideal for applications with steady or predictable traffic patterns, where you can estimate the required capacity in advance.
Query Vs Scan
Query
-
Query Operation: The Query operation allows you to retrieve items from a DynamoDB table based on the values of the primary key attributes. You can specify conditions for filtering the items returned by the query, such as equality conditions or range conditions on the primary key attributes.
-
Efficiency: Queries are more efficient than scans because they retrieve only the items that match the specified key conditions. DynamoDB uses indexes to quickly locate and return the matching items, resulting in fast and predictable performance.
-
Usage Scenario: Queries are best suited for retrieving individual items or ranges of items based on specific criteria, such as fetching a user’s profile by their unique user ID or retrieving all orders placed within a certain date range.
-
Scan
-
Scan Operation: The Scan operation allows you to retrieve all items from a DynamoDB table without specifying any key conditions. It scans through the entire table and examines each item to determine if it meets the optional filtering criteria specified in the request.
-
Efficiency: Scans are less efficient than queries because they examine every item in the table, regardless of whether it matches the filtering criteria. Scans can be resource-intensive, especially for large tables with many items, and may result in higher consumed read capacity units (RCUs).
-
Usage Scenario: Scans should be used sparingly and are typically only necessary when you need to retrieve all items from a table or when you cannot predict the key values of the items you want to retrieve.
💡 Choosing Between Query and Scan: ℹ️ Query: Use Query when you need to retrieve specific items or ranges of items based on known key values. Queries are efficient and provide predictable performance, making them ideal for targeted data retrieval. ℹ️ Scan: Use Scan sparingly and only when necessary, such as when you need to retrieve all items from a table or when you cannot predict the key values of the items you want to retrieve. Scans are less efficient and may consume more resources, especially for large tables.
More Resources
✅ DynamoDb, Explained ✅ The Dynamo DB Book
CloudFormation
AWS CloudFormation is a service provided by Amazon Web Services (AWS) that enables you to provision and manage infrastructure resources using code. It allows you to define your infrastructure as code (IaC) using declarative JSON or YAML templates, called CloudFormation templates, which can be version-controlled and managed like any other codebase.
-
Infrastructure as Code (IaC): CloudFormation allows you to define your entire AWS infrastructure—including virtual servers, networking configurations, databases, security groups, and more … in a declarative template format. This enables you to manage your infrastructure alongside your application code, promoting consistency, repeatability, and automation.
-
Declarative Templates: CloudFormation templates are written in JSON or YAML and describe the desired state of your AWS infrastructure. You specify the resources, their properties, and any dependencies between them in the template. CloudFormation handles the creation, updating, and deletion of resources to ensure that your infrastructure matches the template’s desired state.
-
Stacks: In CloudFormation, a stack is a collection of AWS resources that are created and managed together as a single unit. You deploy a CloudFormation template by creating a stack, and CloudFormation provisions the resources defined in the template within that stack. Stacks enable you to manage related resources in a cohesive and consistent manner.
-
Change Sets: Before making changes to your infrastructure, CloudFormation allows you to preview the changes using Change Sets. A Change Set is a summary of the proposed changes to your stack based on updates to the CloudFormation template. You can review the changes, inspect the differences, and approve or reject them before executing the update.
-
Dependency Management: CloudFormation automatically handles resource dependencies and creates resources in the correct order to satisfy dependencies. For example, if a resource depends on a specific Amazon S3 bucket, CloudFormation ensures that the bucket is created before the dependent resource.
-
Rollback Protection: CloudFormation provides rollback protection to ensure that your stack remains in a consistent state if any part of the update process fails. If an update encounters an error, CloudFormation automatically rolls back the changes to the previous known good state to prevent downtime or inconsistencies.
-
Integration with AWS Services: CloudFormation integrates with various AWS services, allowing you to provision a wide range of resources using templates. You can define resources for compute, storage, networking, database, security, and other services offered by AWS.
Use Cases for AWS CloudFormation:
-
Infrastructure Provisioning: CloudFormation is used for provisioning infrastructure resources, such as virtual servers (EC2 instances), databases (RDS instances), networking configurations (VPCs, subnets, security groups), storage (S3 buckets), and more.
-
Application Deployment: CloudFormation can be used to deploy and manage applications by defining the required infrastructure resources and configurations in templates. This enables automated and repeatable application deployments with consistency and reliability.
-
Environment Management: CloudFormation enables you to manage multiple environments (e.g., development, testing, production) using separate templates and stacks. You can easily replicate environments with consistent configurations and ensure parity across environments.
-
Disaster Recovery: CloudFormation templates can be used to define disaster recovery (DR) configurations, including backup resources, failover mechanisms, and recovery procedures. This helps organizations implement DR solutions that are automated and consistent.
-
Compliance and Governance: CloudFormation templates can enforce compliance and governance policies by specifying resource configurations, access controls, and security settings. This ensures that infrastructure deployments adhere to organizational standards and best practices.
Cognito
Amazon Cognito is a fully managed identity and access management service provided by Amazon Web Services (AWS). It enables you to easily add authentication, authorization, and user management capabilities to your web and mobile applications. Here’s a basic overview of Amazon Cognito:
Key Features of Amazon Cognito
-
User Sign-up and Sign-in: Cognito provides built-in user registration and authentication capabilities. It supports various authentication methods, including username/password, social identity providers (such as Google, Facebook, and Amazon), and federated identity providers (such as SAML and OpenID Connect).
-
User Pools: Cognito User Pools are user directories that manage user registration, authentication, and user profiles for your applications. User Pools allow you to create and maintain a database of users, manage user attributes, customize authentication flows, and handle multi-factor authentication (MFA).
-
Identity Pools (Federated Identities): Cognito Identity Pools allow you to federate identities from external identity providers, such as Amazon, Facebook, Google, or your own identity system. Identity Pools provide temporary AWS credentials that grant access to AWS services, enabling seamless integration with AWS resources for authenticated users.
-
Secure Authentication: Cognito uses industry-standard protocols like OAuth 2.0 and OpenID Connect for authentication, ensuring secure and reliable authentication mechanisms. It also supports encryption of data in transit and at rest to protect user credentials and sensitive information.
-
Multi-Factor Authentication (MFA): Cognito supports multi-factor authentication (MFA) to enhance the security of user authentication. You can enable MFA for user sign-in using methods like SMS, email, or Time-based One-Time Passwords (TOTP), adding an extra layer of security to user accounts.
-
Authorization: Cognito provides fine-grained access control capabilities to manage user access to resources in your applications. You can define custom authorization rules based on user attributes or group membership, allowing you to control which users can access specific features or data.
-
User Profile Management: Cognito allows you to manage user profiles and user attributes, such as email addresses, phone numbers, and custom attributes. You can customize user profiles and store additional user metadata as needed for your applications.
-
Scalability and Availability: Cognito is a fully managed service that automatically scales to handle millions of users and provides high availability across multiple AWS regions. It ensures reliable performance and uptime for your authentication and user management needs.

IAM
Info Who, or What Can access Which AWS resources.
AWS Identity and Access Management (IAM) is a web service provided by Amazon Web Services (AWS) that enables you to securely control access to AWS services and resources. IAM allows you to manage users, groups, roles, and permissions within your AWS environment.
Key Concepts of AWS IAM:
-
Users: IAM users represent individual users or entities within your AWS account. Each user has a unique identity and associated credentials (username and password or access keys) used for authentication and access to AWS services. Users can be assigned permissions to perform specific actions on AWS resources.
-
Groups: IAM groups are collections of IAM users. Instead of assigning permissions to individual users, you can organize users into groups and assign permissions to the groups. This allows you to manage permissions more efficiently and apply consistent access policies across multiple users with similar roles or responsibilities.
-
Roles: IAM roles are entities that define a set of permissions for accessing AWS resources. Unlike users and groups, roles are not associated with specific identities but can be assumed by trusted entities such as AWS services, IAM users, or external users federated through identity providers. Roles are commonly used to grant temporary access to resources or to delegate access across AWS accounts.
-
Policies: IAM policies are JSON documents that define permissions and access controls for AWS resources. Policies can be attached to users, groups, roles, or directly to AWS resources. Policies specify which actions are allowed or denied and which resources the actions can be performed on. IAM policies follow the principle of least privilege, granting only the necessary permissions required for users to perform their tasks.
-
Permissions: IAM permissions determine what actions users, groups, or roles can perform on AWS resources. Permissions are granted by attaching IAM policies to entities such as users, groups, or roles. IAM policies define the actions that are allowed or denied and the resources to which the actions apply.
-
Access Keys: IAM access keys consist of an access key ID and a secret access key, which are used for programmatic access to AWS services via the AWS Command Line Interface (CLI), SDKs, or other tools. Access keys are associated with IAM users and can be used to authenticate and authorize API requests to AWS services.
-
Multi-Factor Authentication (MFA): IAM supports multi-factor authentication (MFA), which adds an extra layer of security to user authentication. MFA requires users to provide a second form of authentication, such as a one-time password generated by a hardware or virtual MFA device, in addition to their regular username and password.
Use Cases for AWS IAM:
-
Identity and Access Management: IAM is used to manage user identities, control access to AWS resources, and enforce security policies within your AWS environment.
-
Security and Compliance: IAM helps enforce security best practices and compliance requirements by controlling access to sensitive data and resources, monitoring user activity, and enforcing least privilege principles.
-
Role-Based Access Control (RBAC): IAM allows you to implement role-based access control (RBAC) by defining roles with specific permissions and assigning them to users or groups based on their roles or responsibilities within the organization.
-
Cross-Account Access: IAM roles can be used to grant access to resources across multiple AWS accounts. This allows you to delegate access to resources in one account to users or services in another account while maintaining security and control.
-
Temporary Access: IAM roles can be used to grant temporary access to resources or services. Temporary security credentials can be generated dynamically and are valid for a limited duration, reducing the risk of unauthorized access and improving security posture.
Setup
Amplify
Setting Up
Initialize a New Project
Initializes a new Amplify project. You will be prompted to enter project details such as environment name, editor, programming language, and framework.
amplify init
Configure Amplify
Configures the AWS Amplify CLI with your AWS account credentials and sets up a new IAM user.
amplify configure
Managing Environments
Create a New Environment
Adds a new environment to your project. You can switch between environments using
amplify env checkout.
amplify env add
List All Environments
Lists all the environments created within the Amplify project.
amplify env list
Checkout an Environment
Switches to a different environment in your project.
amplify env checkout <env-name>
Pull Changes from an Environment
Pulls backend environment configuration changes from the cloud to your local environment. This is useful for ensuring that your local setup matches the cloud environment.
amplify pull
Pushing Updates
Push Local Changes to the Cloud
Pushes your local backend resource changes to the cloud. This command is crucial after you've made changes to your local backend resources and want to synchronize those changes with the cloud.
amplify push
Additional Commands
Adding Features
To add resources such as API, Auth, or Storage to your project, use:
amplify add <category>
For example, to add authentication to your project, you would use:
amplify add auth
Deleting Resources
To remove a resource from your project:
amplify remove <category>
Deleting the Entire Project
To completely remove all resources from your project in the cloud:
amplify delete