What is it ?
Node.js is a cross-platform, open-source JavaScript runtime environment that can run on Windows, Linux, Unix, macOS, and more
Most powerful technology in web development to emerge in the last 10 years
- Enables applications that can handle millions of users without blocking
- From simple webpages to the largest scaled applications, to Windows/Mac desktop apps (with Electron), and hardware (embedded systems)
- Allows us to build entire applications end-to-end in one language - JavaScript
From client side development to full stack development
In this one language, we can now build apps that not only runs on the front-end but also the backend. But this whole process starts somewhere.
Scenario
Let’s think of a scenario, A user opens their browser and wants to send a request to access twitter. A lot of things are happening behind the scene.
-
➡️ What code do they need to load?
-
On the web we need 3 languages to load data
- ✅ HTML : Puts elements on page
- ✅ CSS : Decorate and prettify things
- ✅ JS : Further logic and interaction
-
➡️ Where’s the code/data coming from?
- The data is coming from the server, (which is nothing more than another computer on the internet).
- This computer(server) is always on, and ready to receive a message and send back another message (request, response)
The special always connected computer (server) need to contain codes, codes that are able to introspect the incoming message ( request) and respond accordingly to the message with another message (response). The language you can write to control this behaviors are :
- 💡 PHP
- 💡 Python
- 💡 Java
- 💡 Ruby
- 💡 C/C++
- 💡 JavaScript
- ➡️ Where does the special message arrive from ?
- 💡 The special message when coming to my server, it lands on my network card, We need a way to reach out to our network card and pull it out. I need to access the internal features.
- 🔥 JavaScript Does not have the abilities of accessing the internal features, (files, network etc…)
- 💡 C++ does. We are going to have to make use of C++ to control the internal features.
- [p] Node is nothing other than JavaScript with C++ features.
C++ has many features that let it directly interact with the OS directly, JavaScript does not! So it has to work with C++ to control these computer features. What is this combination known as? ... Node.js JS -> Node -> Computer feature (e.g. network, file system)
We are going to write JavaScript that indirectly controls the internal features through node, that on it's other hand controls C++ features that do the heavy liftin.
Node mainly does 3 things
- [p] Saves data and functionality (code)
- These are our codes that need to be executed later.
- 💡 It saves them to the Store of data/Memory also known as Global variable environment
- [p] Uses that data by running functionality (code) on it
- Use the saved data to perform some operations
- 🔥 Has a ton of built-in labels that trigger Node features that are built in C++ to use our computer’s internals
Let’s see what JavaScript does :
let num = 3
// 1. Save a function (code to run, parameters awaiting inputs)
function multiplyBy2(inputNumber) {
const result = inputNumber * 2
return result
}
// 2a. Call/run/invoke/execute a function (with parens)
// and 2b. insert an input (an argument)
const output = multiplyBy2(num)
const newOutput = multiplyBy2(10)
JavaScript other talent is to trigger node built-in features.
We can set up, with a JavaScript label, a Node.js feature (and so computer internals) to wait for requests for html/css/js/tweets from our users
- 🔥 How?
- ➡️ The most powerful built-in Node feature of all: http (and its associated built-in label in JS also http, conveniently)
Using HTTP feature of node to set up open socket
What is a Socket ?: A network socket is a software structure within a network node of a computer network that serves as an endpoint for sending and receiving data across the network
We need to open a network socket connection in such a way that, whenever an inbound request comes in from the web, we can run code to send back a message.
const server = http.createServer()
server.listen(80)
// The createServer simply opens the socket connection and returns an object in JS that has a bunch of methods we can directly access in our js Methos such as : Listen,Inbound web request ⇾ run code to send back message This, simply triggers the C++ feature to open a web Socket connection on a given port to listen for incoming requests.
Folk, we are not ready to receive requests, in exactly two lines!!
Opening a channel to the internet at a particular entry point!, super sophisticated stuff going on here!
Bundle code in a function and let node execute it for us.
We have no idea of when an incoming message is going to come in !
We would write our program in such a way that we get to check if there is an incoming message and run some code accordingly. But here is a problem, we don’t know when this is going to happen, it can be now, it can be in 3 Minutes or 300 Days from now. Nobody knows. but node knows.
Node auto-runs the code (function) for us when a request arrives from a user
- [?] We don’t know when the inbound request would come.
- ➡️ we have to rely on Node to trigger JS code to run
- [?] JavaScript is single-threaded & synchronous.
- ➡️ All slow work (e.g. speaking to a database, accessing the file system) is done by Node in the background (more on this later)
// Function that will be called everytime there is an incoming request
function doOnIncoming(incomingData, functionsToSetOutgoingData) {
functionsToSetOutgoingData.end("Welcome to Twitter!")
}
// Start our socket connection and give it our function that will be called whenever there is an incoming request.
const server = http.createServer(doOnIncoming)
server.listen(80)- Two parts to calling a function
- Executing its code
- Inserting input (arguments)
Node not only will auto-run our function at the right moment, it will also automatically insert whatever the relevant data is as the additional argument (input)
Sometimes it will even insert a set of functions in an object (as an argument) which give us direct access to the message (in Node) being sent back to the user and allows us to add data to that message
And that is exactly what node does with its http feature
Node inserts the arguments (inputs) automatically in the function it auto-runs:
- [f] ‘Inbound object’: all data from the inbound (request) message
- [f] Inbound object : all data from the inbound (request) message
These objects (the arguments to the auto-run function) aren’t given labels by Node. So how do we access them? We do so with parameters (placeholders).
We must make sure to format the function Node auto-runs the way Node expects (use docs)
function doOnIncoming(incomingData, functionsToSetOutgoingData) {
functionsToSetOutgoingData.end("Welcome to Twitter!")
}
const server = http.createServer(doOnIncoming)
server.listen(80)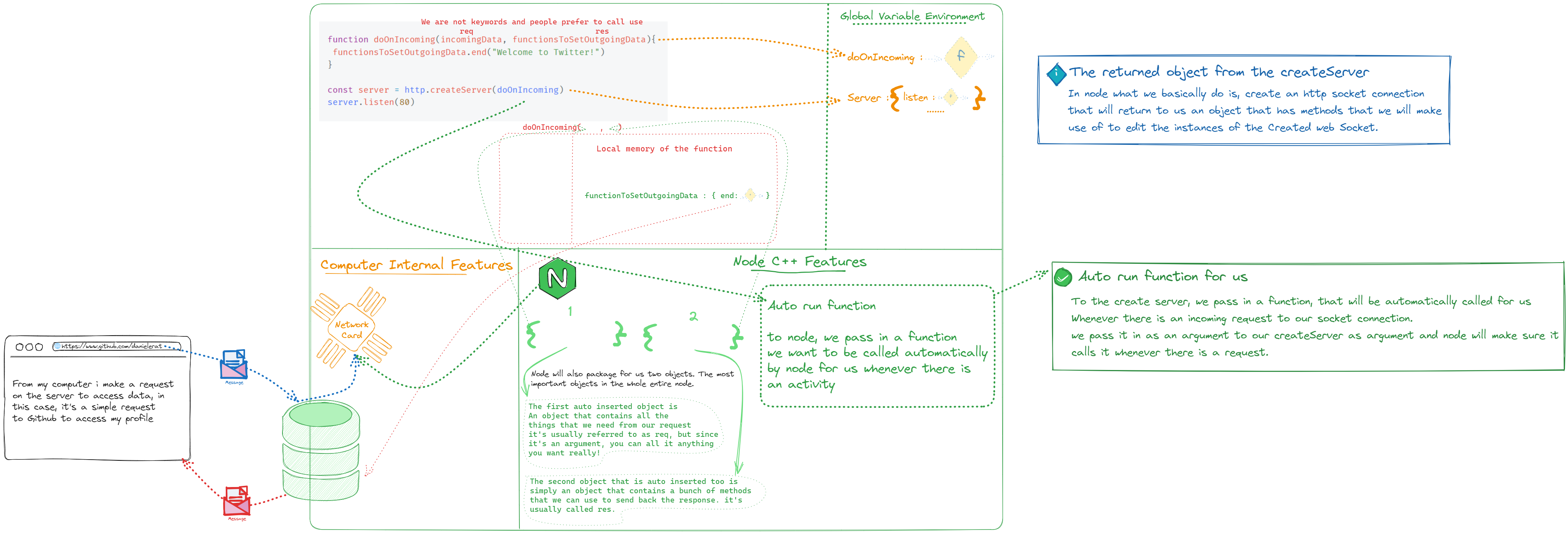
HTTP format
Messages are sent in HTTP format, The ‘protocol’ for browser-server interaction
HTTP requests
An HTTP request is made by a client, to a named host, which is located on a server. The aim of the request is to access a resource on the server.
To make the request, the client uses components of a URL (Uniform Resource Locator), which includes the information needed to access the resource. The components of a URL explains URLs.
A correctly composed HTTP request contains the following elements:
- [f] A request line.
- [f] A series of HTTP headers, or header fields.
- [f] A message body, if needed.
Each HTTP header is followed by a carriage return line feed (CRLF). After the last of the HTTP headers, an additional CRLF is used (to give an empty line), and then any message body begins.
Request line
The request line is the first line in the request message. It consists of at least three items:
- 💡 A method.
- ➡️ The method is a one-word command that tells the server what it should do with the resource. For example, the server could be asked to send the resource to the client.
- 💡 The path component of the URL for the request.
- ➡️ The path identifies the resource on the server.
- 💡 The HTTP version number,
- ➡️ showing the HTTP specification to which the client has tried to make the message comply.
An example of a request line is:
GET /software/htp/cics/index.html HTTP/1.1In this example:
- the method is
GET - the path is
/software/htp/cics/index.html - the HTTP version is
HTTP/1.1
A request line might contain some additional items:
- A query string. This provides a string of information that the resource can use for some purpose. It follows the path, and is preceded by a question mark.
- The scheme and host components of the URL, in addition to the path. When the resource location is specified in this way, it is known as the absolute URI form. For HTTP/1.1, this form is used when a request will go through a proxy server. Also for HTTP/1.1, if the host component of the URL is not included in the request line, it must be included in the message in a Host header.
HTTP headers
Additional metadata from the sender's computer
HTTP headers are written on a message to provide the recipient with information about the message, the sender, and the way in which the sender wants to communicate with the recipient. Each HTTP header is made up of a name and a value. The HTTP protocol specifications define the standard set of HTTP headers, and describe how to use them correctly. HTTP messages can also include extension headers, which are not part of the HTTP/1.1 or HTTP/1.0 specifications.
The HTTP headers for a client’s request contain information that a server can use to decide how to respond to the request. For example, the following series of headers can be used to specify that the user only wants to read the requested document in French or German, and that the document should only be sent if it has changed since the date and time when the client last obtained it:
Accept-Language: fr, de
If-Modified-Since: Fri, 10 Dec 2004 11:22:13 GMTAn empty line (that is, a CRLF alone) is placed in the request message after the series of HTTP headers, to divide the headers from the message body.
Message body
The body content of any HTTP message can be referred to as a message body or entity body. Technically, the entity body is the actual content of the message. The message body contains the entity body, which can be in its original state, or can be encoded in some way for transport, such as by being broken into chunks (chunked transfer-coding). The message body of a request may be referred to for convenience as a request body.
Message bodies are appropriate for some request methods and inappropriate for others. For example, a request with the POST method, which sends input data to the server, has a message body containing the data. A request with the GET method, which asks the server to send a resource, does not have a message body.
Events & Error Handling
When dealing with a server or someone else's computer, there is a thousand thing that can go wrong in that process, We need to handle these scenarios accordingly.
How can we handle this? We need to understand our background Node http server feature better ?
What triggers the function call ?
Much of the Node.js core API is built around an idiomatic asynchronous event-driven architecture in which certain kinds of objects (called "emitters") emit named events that cause
Functionobjects ("listeners") to be called.
Understanding http.createServer(doOnIncoming)
In Node.js, the http module provides the ability to create HTTP servers. The http.createServer([options][, requestListener]) method initializes a new instance of an HTTP server. The requestListener is a function which is automatically added to the ’request’ event.
When you pass
doOnIncomingas therequestListener, you’re telling Node.js to execute this function every time the server receives an HTTP request.
const http = require("http")
const doOnIncoming = (req, res) => {
// Handle the request here
res.writeHead(200, { "Content-Type": "text/plain" })
res.end("Hello, World!\n")
}
const server = http.createServer(doOnIncoming)
server.listen(3000, () => {
console.log("Server running at http://localhost:3000/")
})The Triggered Event: ‘request’
The event that gets triggered to execute doOnIncoming is the ‘request’ event.
This event is emitted by the HTTP server every time it receives an HTTP request.
The ‘request’ event passes two objects to the callback function:
-
req(http.IncomingMessage):- An object representing the HTTP request. It contains properties and methods for accessing request details such as headers, URL, and method.
-
res(http.ServerResponse):- An object that can be used to craft an HTTP response, including setting headers and sending the response body back to the client.
Under the Hood: What Happens When http.createServer(doOnIncoming) is Called?
- Initialization: When
http.createServer()is called, Node.js initializes a new instance of an HTTP server (http.Server). This involves setting up the necessary infrastructure to handle incoming network connections. - Event Emitter Setup: The HTTP server instance is an instance of
EventEmitter. By passingdoOnIncomingas a request listener, you effectively subscribe to the ‘request’ event. Node.js uses the Observer pattern here, where the HTTP server emits events and the functions (observers) that listen to these events react accordingly. - Listening for Connections: Once the server starts listening on a port (via
server.listen(port)), Node.js’s event loop begins to wait for incoming network connections on that port. - Handling Requests: Upon receiving a new HTTP request, the server emits a ‘request’ event. Because
doOnIncomingis registered as a listener for this event, it gets executed. InsidedoOnIncoming, you have the full context of the request (req) and the tools to send a response (res). - Stream Handling: The request (
req) and response (res) objects are both streams. This design allows efficient processing of data, especially useful for handling large files or real-time data without excessive memory consumption. - Asynchronous Nature: Node.js operates in a non-blocking, event-driven manner. This means that while your
doOnIncomingfunction processes a request, the server can simultaneously handle other events, like new incoming connections, making it highly scalable for I/O-intensive operations.
What happens for the function doOnIncoming to get triggered ?
function doOnIncoming(incomingData, functionsToSetOutgoingData) {
functionsToSetOutgoingData.end("Welcome to Twitter!")
}
const server = http.createServer(doOnIncoming)
server.listen(80)Turns out, the above is just a short version of this manual form :
function doOnIncoming(incomingData, functionsToSetOutgoingData){
functionsToSetOutgoingData.end("Welcome to Twitter")
}
function doOnError(infoOnError){
console.error(infoOnError)
}
const server = http.createServer();
server.listen(80)
server.on('request', doOnIncoming)
server.on('clientError', doOnError)
> ```
> An event gets emitted whenever there is an incoming message, if the message is valid then '**request**' message gets triggered, otherwise it's the **clientError** that gests triggered.
> [!question] What happens when we use http.createServer() ?
>
> What truly happens is that, using that function, it not only sets up a socket connection to receive and respond to incoming requests, but also returns an object that contains methos, that we can use later on, to modify the background features (or the node c++ features) of our server.
We have much of our twitter app set up now handling, inspecting and responding to these
messages (‘requests’) is the core of our app, of Node, and of servers
- [ ] But, Node can do even more. We have an archive of tweets stored in a huge file (1.5GB)
- [ ] Unfortunately they’re saved on our computer, not in our little JavaScript-specific data store (JavaScript memory)
- [ ] Could we load them into JavaScript to run a function that removes bad tweets?
- [ ] We can use fs to do so but there might be some issues with a file that large
## Stream & Buffer
What if Node used the ‘**event**’ (messagebroadcasting) pattern to send out a message (‘**event**’) each time a sufficient batch of the JSON data had been loaded in ?
```js
let cleanedTweets = "";
function cleanTweets (tweetsToClean){
// algorithm to remove bad tweets from `tweetsToClean`
}
function doOnNewBatch(data){
cleanedTweets += cleanTweets(data);
}
const accessTweetsArchive = fs.createReadStream('./tweetsArchive.json')
accessTweetsArchive.on('data', doOnNewBatch);This would have the effect of processing our data while more data are being loaded from the stream ! What if this was possible? 🥰
In Node.js, streams are a fundamental concept for handling data flow, especially when dealing with large amounts of data or data that’s received or sent incrementally. Streams allow you to read from or write to a continuous flow of data in chunks, rather than loading the entire dataset into memory all at once. This is particularly useful when working with files, network connections, or any other source of data that may be too large to handle in memory.
-
Breaking Down Data into 64KB Chunks:
- When data is read from a stream in Node.js, it’s typically broken down into smaller, manageable chunks. By default, the chunk size is often around 64KB, but this can vary depending on factors like the underlying operating system and the specific implementation of streams being used.
- The reason for breaking data into chunks is to optimize memory usage and processing. Instead of waiting for the entire dataset to be read into memory before processing it, Node.js can start processing each chunk as it becomes available. This allows for more efficient memory utilization and enables applications to handle data of virtually any size without running into memory constraints.
Continuous Function Calls for Stream Processing:
In Node.js, when you consume data from a stream, you typically register event handlers to handle incoming data. The data event is a common event that’s emitted whenever new data is available to be read from the stream. When you register a callback function for the data event, Node.js will automatically call that function whenever new data is received, allowing you to process the data incrementally.
Here’s a simplified example:
const fs = require("fs")
const readableStream = fs.createReadStream("example.txt")
readableStream.on("data", (chunk) => {
// Process each chunk of data here
console.log("Received chunk:", chunk)
})
readableStream.on("end", () => {
console.log("No more data to read")
})In this example, createReadStream creates a readable stream from a file (example.txt). The 'data' event listener is triggered each time a chunk of data is available to be read from the stream.
The callback function provided to this event handler is then executed, allowing you to process each chunk of data as it arrives. This process continues until all data has been read from the stream, at which point the 'end' event is emitted.
How Data is Pulled from the Source:
Under the hood, Node.js uses various mechanisms to pull data from a data source into a stream. For example:
- File System: When reading from a file, Node.js may use operating system APIs to read data in chunks from the file and push those chunks into the stream.
- Network Socket: When reading from a network socket (e.g., HTTP requests), Node.js may use event-driven I/O to asynchronously receive data from the network and push it into the stream.
- Custom Streams: Developers can also create custom readable streams to pull data from other sources, such as databases, sensors, or external APIs.
Regardless of the data source, Node.js abstracts away the details of how data is retrieved and provides a consistent interface for working with streams, allowing you to focus on processing the data rather than the underlying I/O operations.
Streams
A stream is a sequence of data that is being moved from one point to another over time
- A stream of data over the internet being moved from one computer to another
- A stream of data being transferred from one file to another within the same computer
In node, The idea is to process the stream of data as they arrive instead of waiting for the entire data to be available before processing
- Watching video on YouTube
- The data arrives in chunks, and you watch in chunks while the rest of the data arrives over time. You don’t wait for the entire video to be loaded before you can start watching.
- Transferring file contents from fileA to fileB
- You don’t load the entire content in memory so that you can start transferring them, the contents arrive in chunks, and you transfer in chunks while the remaining content arrive over time.
This have the advantage of Preventing unnecessary data downloads and memory usage
Buffer
In Node.js, a buffer is a temporary storage location in memory that is used to temporarily hold data while it is being moved from one place to another. Buffers are particularly useful when dealing with binary data, such as when reading from or writing to files, working with network protocols, or handling raw data in other formats.
A buffer in Node.js is essentially a way to represent binary data, which is data stored in the form of bytes. It provides a way to work with raw binary data directly in JavaScript, which is traditionally a language focused on text-based data
The idea behind buffer
Node.js cannot control the pace at which data arrives in the stream, it can only decide when is the right time to send the data for processing. If there is data already processed or too little data to process, Node puts the arriving data in a buffer.
It is an intentionally small area that Node maintains in the runtime to process a stream of data.
- Streaming a video online.
- ➡️ If your internet connection is fast enough, the speed of the stream will be fast enough to instantly fill up the buffer and send it out for processing.
- 💡 That will repeat till the stream is finished.
- ➡️ If your connection is slow, after processing the first chunk of data that arrived, the video player will display a loading spinner which indicates it is waiting for more data to arrive. Once the buffer is filled up and the data is processed, the video player shows the video.
- ➡️ While the video is playing, more data will continue to arrive and wait in the buffer
How does it work ?
When you create a buffer in Node.js, you allocate a fixed-size chunk of memory. This memory can then be read from or written to using various methods provided by the Buffer class.
Here’s a basic example of creating a buffer in Node.js:
// Create a buffer with 10 bytes
const buf = Buffer.alloc(10)
// Write data to the buffer
buf.write("Hello")
// Read data from the buffer
console.log(buf.toString()) // Output: HelloBuffer.alloc(10)allocates a buffer of size 10 bytes.buf.write('Hello')writes the string “Hello” into the buffer.buf.toString()converts the buffer data back to a string, so it can be printed to the console.
Another example
const buffer = new Buffer.from("Daniel", "utf8")
console.log(buffer)
// Buffer in hexadecimal representation
// <Buffer 44 61 6e 69 65 6c>
console.log(buffer.toJSON())
/*
{
type: 'Buffer',
data: [ 68, 97, 110, 105, 101, 108 ]
}
*/Key Concepts and Operations:
- Creating Buffers: Buffers can be created using various methods like
Buffer.alloc(),Buffer.from(), or by directly allocating memory. - Reading and Writing: Buffers can be read from or written to using methods like
write(),readUInt8(),toString(), etc. - Fixed Size: Buffers have a fixed size, meaning that once allocated, their size cannot be changed.
- Raw Binary Data: Buffers hold raw binary data, which means they can store any kind of data, not just text.
- Efficient Data Manipulation: Buffers provide efficient methods for manipulating binary data, such as copying, slicing, and converting to other formats.
- Buffer Pools: Node.js uses buffer pools to efficiently manage memory allocation for buffers, reducing overhead when creating and destroying buffers frequently.
Error handling in node
Applications running in Node.js will generally experience four categories of errors:
- ➡️ Standard JavaScript errors such as EvalError, SyntaxError, RangeError, ReferenceError, TypeError, and URIError
- ➡️ System errors triggered by underlying operating system constraints such as attempting to open a file that does not exist or attempting to send data over a closed socket.
- ➡️ User-specified errors triggered by application code.
- ➡️
AssertionErrors are a special class of error that can be triggered when Node.js detects an exceptional logic violation that should never occur. These are raised typically by thenode:assertmodule.
All JavaScript and system errors raised by Node.js inherit from, or are instances of, the standard JavaScript Error class and are guaranteed to provide at least the properties available on that class.
Error propagation and interception.
Node.js supports several mechanisms for propagating and handling errors that occur while an application is running. How these errors are reported and handled depends entirely on the type of Error and the style of the API that is called.
All JavaScript errors are handled as exceptions that immediately generate and throw an error using the standard JavaScript throw mechanism. These are handled using the try…catch construct provided by the JavaScript language.
// Throws with a ReferenceError because z is not defined.
try {
const m = 1
const n = m + z
} catch (err) {
// Handle the error here.
}Any use of the JavaScript
throwmechanism will raise an exception that must be handled or the Node.js process will exit immediately.
Tips and Tricks
Node console log
Node was not built to put JS on the server.
Ryan Dahl said to build a high throughput low latency socket server, back in the days, he knew Ruby and that is the one he was using to build node. He realized that he needed this concept of event loop to make this idea of Asynchronicity to work. But back in the days, Ruby did not have that, So he was essentially building the event loop for Ruby, until he realize that JS already had that in place, and switched to JavaScript. It was not because he wanted to put JS on the server.
High throughput low latency IO tasks
The event loop shines for IO-bound tasks due to its ability to efficiently handle situations where tasks spend significant time waiting for external resources, like network requests or disk access.
1. Non-Blocking Operations:
- Unlike traditional approaches where a task waits for an IO operation to complete before moving on, the event loop allows tasks to initiate the operation and then immediately return control to the loop.
- This frees up the thread to handle other tasks while the IO operation is ongoing.
2. Event-Driven Execution:
- The event loop continuously monitors for events indicating the completion of IO operations or the availability of data.
- When an event occurs, the loop schedules the corresponding callback function associated with that task for execution.
3. Efficient Resource Utilization:
- By avoiding blocking, the event loop maximizes the utilization of a single thread for handling multiple IO-bound tasks concurrently.
- This is particularly beneficial in environments with limited threads, as it prevents tasks from hogging resources while waiting for IO.
4. Scalability and Responsiveness:
- The event loop can handle a large number of concurrent IO operations without compromising responsiveness.
- This allows applications to scale efficiently as the number of requests or concurrent connections increases.
Here’s an analogy:
Imagine a restaurant with a single waiter. In a traditional approach, the waiter would take one order at a time, wait for the food to be prepared, deliver it to the customer, and then take the next order. This creates long wait times for customers.
With an event loop, the waiter can take multiple orders simultaneously, send them to the kitchen, and then come back to take more orders while waiting for the previous ones to be prepared. As soon as an order is ready, the waiter is notified and can deliver it to the customer, ensuring efficient service even during peak hours.
In summary, the event loop's ability to handle non-blocking operations, leverage event-driven execution, and efficiently utilize resources makes it a compelling choice for applications heavily reliant on IO-bound tasks.